mmpretrain 사용법 (1)
mmpretrain 사용법 (1)
mmpretrain study.

mmpretrain 사용법(1)
mmpretrain 설치 후에 documentation 으로 주요 개념에 대해 공부했다.
아직은 제대로 이해하지 못했지만 스터디한 것에 대해 주요 개념을 정리해본다.
자세한 내용은 documentation을 참조하자.
Config 파일
딥러닝 실험과 관련된 구성 관리를 파이썬 기반의 Config 파일로 관리한다고하며,
이러한 파일들은 configs 폴더에 있으며, 아래 그림은 해당 폴더의 구조를 보여준다.
대충 _base_폴더(datasets, models, schedules, default_runtime)와 알고리즘 폴더들로 구성되어있다.

Config Structure
configs 폴더의 _base_에는 models, datasets, schedules 폴더 3개와 default_runtime.py 파일이 있다.
_base_ 에 있는 폴더와 파일을 primitive config file이라고 한다.
아래 그림은 ResNet50 config file을 보여준다. (..\mmpretrain\configs\resnet\resnet50_8xb32_in1k.py)
_base_ = [ # This config file will inherit all config files in `_base_`.
'../_base_/models/resnet50.py', # model settings
'../_base_/datasets/imagenet_bs32.py', # data settings
'../_base_/schedules/imagenet_bs256.py', # schedule settings
'../_base_/default_runtime.py' # runtime settings
]
먼저, 각각에 대해 정리해보자.
Model settings
- 네트워크 구조나 loss function과 관련된 정보들이 있다.
- 구축할 모델의 classification, self-supervised,이미지 검색 등의 다양한 작업을 지원한다.
ImageClassifier 기준으로 예시를 설명하고 있다.
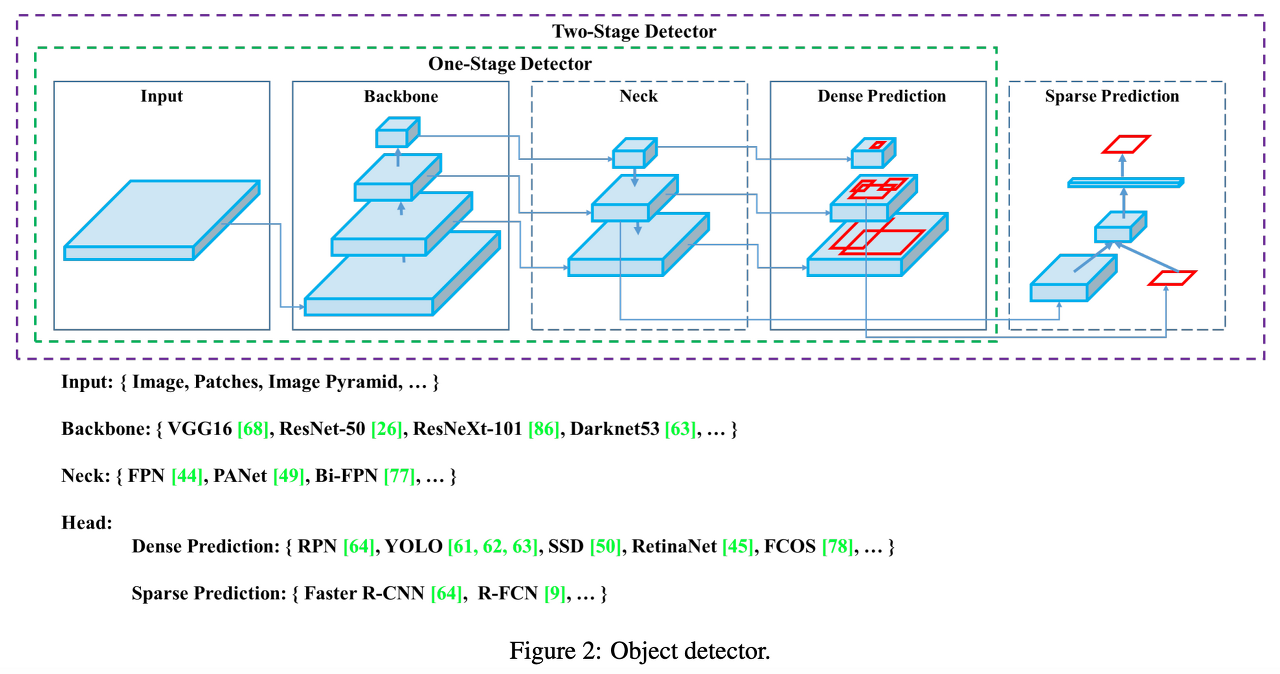
아래 5가지 부분에 대해 알맞게 수정해주어야하며, 그림은 backborn, neck, head에 대한 그림이다.
1. backborn 설정 : ResNet, Swin Transformer, Vision Transformer 같은 main network
2. neck 설정 : backborn과 head 중간 연결 부분
3. head 설정 : classification, self-supervised training, loss 등과 관련 된 부분
4. data_preprocessor 설정 : 모델 전에 입력 전처리 관련된 부분
5. train_cfg 설정 : 훈련 중 이미지 분류기의 추가 설정 부분
아래 코드는 documentation에 있는 configs\_base_\models\resnet50.py 에 있는 파일이다.
model 딕셔너리에서 backborn, neck, head 등 필요에 맞게 수정해 주면된다.
model = dict(
type='ImageClassifier', # The type of the main model (here is for image classification task).
backbone=dict(
type='ResNet', # The type of the backbone module.
# All fields except `type` come from the __init__ method of class `ResNet`
# and you can find them from https://mmpretrain.readthedocs.io/en/latest/api/generated/mmpretrain.models.backbones.ResNet.html
depth=50,
num_stages=4,
out_indices=(3, ),
frozen_stages=-1,
style='pytorch'),
neck=dict(type='GlobalAveragePooling'), # The type of the neck module.
head=dict(
type='LinearClsHead', # The type of the classification head module.
# All fields except `type` come from the __init__ method of class `LinearClsHead`
# and you can find them from https://mmpretrain.readthedocs.io/en/latest/api/generated/mmpretrain.models.heads.LinearClsHead.html
num_classes=1000,
in_channels=2048,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
))
Data settings
- 이 premitive config file은 dataloader 와 evluator에 대한 정보가 있으며, 세부적인 내용은 아래와 같다.
자세한 내용은 documentation 참조하자.
. data_preprocessor : model.data_preprocessor와 동일하지만 우선순위가 낮음
. train_evaluator | val_evaluator | test_evaluator
. train_dataloader | val_dataloader | test_dataloader
* batch_size
* num_workers
* sampler
* persistent_workers
* dataset : type(CustomDataset, ImageNet ...), pipeline (data transfrom pipeline)
아래 코드는 mmpretrain\configs\_base_\datasets\imagenet_bs32.py 의 내용이다.
역시 내 환경에 맞게 잘 수정해줘야한다.
dataset_type = 'ImageNet'
# preprocessing configuration
data_preprocessor = dict(
# Input image data channels in 'RGB' order
mean=[123.675, 116.28, 103.53], # Input image normalized channel mean in RGB order
std=[58.395, 57.12, 57.375], # Input image normalized channel std in RGB order
to_rgb=True, # Whether to flip the channel from BGR to RGB or RGB to BGR
)
train_pipeline = [
dict(type='LoadImageFromFile'), # read image
dict(type='RandomResizedCrop', scale=224), # Random scaling and cropping
dict(type='RandomFlip', prob=0.5, direction='horizontal'), # random horizontal flip
dict(type='PackInputs'), # prepare images and labels
]
test_pipeline = [
dict(type='LoadImageFromFile'), # read image
dict(type='ResizeEdge', scale=256, edge='short'), # Scale the short side to 256
dict(type='CenterCrop', crop_size=224), # center crop
dict(type='PackInputs'), # prepare images and labels
]
# Construct training set dataloader
train_dataloader = dict(
batch_size=32, # batchsize per GPU
num_workers=5, # Number of workers to fetch data per GPU
dataset=dict( # training dataset
type=dataset_type,
data_root='data/imagenet',
ann_file='meta/train.txt',
data_prefix='train',
pipeline=train_pipeline),
sampler=dict(type='DefaultSampler', shuffle=True), # default sampler
persistent_workers=True, # Whether to keep the process, can shorten the preparation time of each epoch
)
# Construct the validation set dataloader
val_dataloader = dict(
batch_size=32,
num_workers=5,
dataset=dict(
type=dataset_type,
data_root='data/imagenet',
ann_file='meta/val.txt',
data_prefix='val',
pipeline=test_pipeline),
sampler=dict(type='DefaultSampler', shuffle=False),
persistent_workers=True,
)
# The settings of the evaluation metrics for validation. We use the top1 and top5 accuracy here.
val_evaluator = dict(type='Accuracy', topk=(1, 5))
test_dataloader = val_dataloader # The settings of the dataloader for the test dataset, which is the same as val_dataloader
test_evaluator = val_evaluator # The settings of the evaluation metrics for test, which is the same as val_evaluator
Schedule settings
- 이 파일은 training strategy settings 와 training, val, test loop에 대한 setting 파일이다.
- 아래는 주요 파일의 주요 구성 내용으로 자세한 내용은 documentation 참조하자.
. optim_wrapper
* optimizer
* paramwise_cfg : 파라미터의 유형 또는 이름에 따라 다른 최적화 인수를 설정
* accumulative_counts
. param_scheduler : learning rate, momentum curves
. train_cfg | val_cfg | test_cfg
아래 코드는 mmpretrain\configs\_base_\datasets\imagenet_bs32.py 파일 내용이다.
optim_wrapper = dict(
# Use SGD optimizer to optimize parameters.
optimizer=dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001))
# The tuning strategy of the learning rate.
# The 'MultiStepLR' means to use multiple steps policy to schedule the learning rate (LR).
param_scheduler = dict(
type='MultiStepLR', by_epoch=True, milestones=[30, 60, 90], gamma=0.1)
# Training configuration, iterate 100 epochs, and perform validation after every training epoch.
# 'by_epoch=True' means to use `EpochBaseTrainLoop`, 'by_epoch=False' means to use IterBaseTrainLoop.
train_cfg = dict(by_epoch=True, max_epochs=100, val_interval=1)
# Use the default val loop settings.
val_cfg = dict()
# Use the default test loop settings.
test_cfg = dict()
# This schedule is for the total batch size 256.
# If you use a different total batch size, like 512 and enable auto learning rate scaling.
# We will scale up the learning rate to 2 times.
auto_scale_lr = dict(base_batch_size=256)
Runtime settings
- 이 파일은 checkpoint strategy, log configuration, training parameters, breakpoint weight path, working directory 등을 설정하는 파일이다.
- 아래 코드는 mmpretrain\configs\_base_\default_runtime.py 파일이다.
# defaults to use registries in mmpretrain
default_scope = 'mmpretrain'
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type='IterTimerHook'),
# print log every 100 iterations.
logger=dict(type='LoggerHook', interval=100),
# enable the parameter scheduler.
param_scheduler=dict(type='ParamSchedulerHook'),
# save checkpoint per epoch.
checkpoint=dict(type='CheckpointHook', interval=1),
# set sampler seed in a distributed environment.
sampler_seed=dict(type='DistSamplerSeedHook'),
# validation results visualization, set True to enable it.
visualization=dict(type='VisualizationHook', enable=False),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi-process parameters
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend='nccl'),
)
# set visualizer
vis_backends = [dict(type='LocalVisBackend')] # use local HDD backend
visualizer = dict(
type='UniversalVisualizer', vis_backends=vis_backends, name='visualizer')
# set log level
log_level = 'INFO'
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
Use intermediate variables in configs
intermediate variable을 사용하면 config 파일이 더 명확해진다고 한다.
예를 들어, train_pipeline / test_pipeline은 intermediate variables 이다.
train_pipeline / test_pipeline을 먼저 정의하고, train_dataloader / test_dataloader를 전달하면,
training, testing 중에 이미지 사이즈를 수정하길 원하면 intermediate 변수를 수정해야한다고 한다.
음... 솔직히 이해가 잘 안되는데, 나중에 다시 보자.
Ignore som fields in the base configs
기본 config 파일에서 domain content를 무시하려면 _delete_ = True 를 설정해야한다.
예를 들어, ResNet50 에서 코사인 스케줄을 사용하려면, 상속을 사용하여 직접 수정하는 것만으로 'step' 오류
발생하는데, 이는 param_scheduler 도메인 정보 내 기본 설정의 'step' 필드가 예약 되어 있이 때문이다.
관련 필드 내용을 무시하려면 _delete_ = True 설정을 해줘야한다.
뭔가 중복이 되서 오류가 발생하는것 같은데, 오류를 보고 이 문서를 다시 참조해보자.
아래는 _delete_ = True 예지이다.
_base_ = '../../configs/resnet/resnet50_8xb32_in1k.py'
# the learning rate scheduler
param_scheduler = dict(type='CosineAnnealingLR', by_epoch=True, _delete_=True)
Use some fields in the base configs
정의 중복을 피하기 위해 _base_ 파일의 일부 필드를 참조하는 경우가 있다.
아래는 training data preprocsssing pipeline에서 auto augmentation의 예를 보여준다.
_base_에 _randaug_policies.py을 추가한 후, config 파일 내의 변수를 참조하여
_base_.auto_incresing_policies를 사용하면 된다고 한다.
사실 정확히 이해가 안된다. 나중에 직접 해보면서 다시 정리해야겠다.
_base_ = [
'../_base_/models/resnest50.py', '../_base_/datasets/imagenet_bs64.py',
'../_base_/default_runtime.py', './_randaug_policies.py',
]
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='RandAugment',
policies=_base_.policies, # This uses the `policies` parameter in the primitive config.
num_policies=2,
magnitude_level=12),
dict(type='EfficientNetRandomCrop', scale=224, backend='pillow'),
dict(type='RandomFlip', prob=0.5, direction='horizontal'),
dict(type='ColorJitter', brightness=0.4, contrast=0.4, saturation=0.4),
dict(
type='Lighting',
eigval=EIGVAL,
eigvec=EIGVEC,
alphastd=0.1,
to_rgb=False),
dict(type='PackInputs'),
]
train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
Modify config in command
tools/train.py, tools/test.py 파일을 사용하는 경우, --cfg-options 인수를 지정하여 config 파일의 내용을 직접
수정이 가능하다.
명령어에 [ --cfg-options 변경할 내용 ] 을 추가하면 된다.
예를 들어, 아래와 같이 옵션을 주면 변경 가능하다.
--cfg-options model.backbone.norm_eval=False
- Update config keys of dict chains.
- Update keys inside a list of configs
- Update values of list/tuples
Reference
https://arxiv.org/pdf/2004.10934.pdf
https://mmpretrain.readthedocs.io/en/latest/user_guides/config.html